

Anomaly detection can save businesses big money.
In 2020, fraud losses totaled US$10.24 billion in the US alone—up from US$9.62 billion in 2019. And Deloitte only sees these losses increasing, with the cost of cybercrime expected to grow to US$10.5 trillion by 2025. This number is based on the fact that the average cost of a single data breach in 2021 was US$4.24 million.
Anomaly detection can help curtail these kinds of financial losses by detecting outliers or unusual patterns in a dataset. In this case, the usual usage pattern would include information such as transaction amounts and the location of transactions.
In this piece, we provide a rundown of what anomaly detection is, how it fits into the wider data science sphere, and a step-by-step guide on how to carry out analysis and mining to effectively detect anomalies in data.
Let’s dive in.
Why is it important to address anomaly detection?
Anomaly detection and rules-based methods can help to combat fraud, corruption, and abuse for more than 20 years. They’re powerful tools, but they still have their limits.
These days, nearly every data log engaged leaves behind digital fingerprints. This presents a significant opportunity for companies to prevent further harm. However, it’s often only considered after the damage has already been done.
Nowadays, anomaly detection is of great interest to diverse industry fields. Using multiple machine learning algorithms, the practice aims to identify regions of data with unexpected behaviors or patterns.
Leaders in numerous industries can take advantage of these new tools and technologies to harness potential problems before they fully unfold, thereby minimizing damage. For example:
- As we mentioned before, credit card companies can use anomaly detection to flag unauthorized transactions.
- The manufacturing industry can use anomaly detection to reduce defects, lower equipment downtime, and optimize energy consumption.
- Government agencies and other companies with protected information can use anomaly detection to flag Distributed Denial-of-Service (DDoS) attacks.
However, often an in-house technical team lacks the general context of the data distribution problem and how to address it correctly using available machine learning models.
What are the differences between outlier and anomaly detection?
Outlier and anomaly detection are related concepts that are widely misunderstood. They detect whether a new observation belongs to the same distribution as the existing observations (an inlier), or should be considered as different (an outlier).
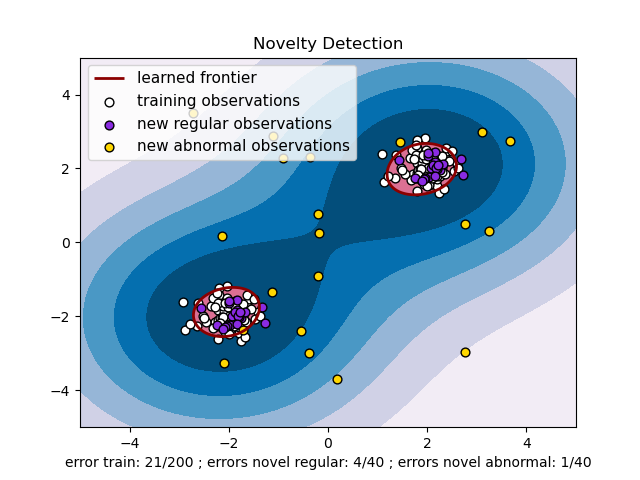
In the literature, these techniques differ. When using anomaly detection, you have access to the correct-clean distribution. With this information, you can learn the frontier, delimiting the contour of the distribution of the initial observations plotted in embedding p-dimensional space.
Then, if further observations lay within the frontier-delimited subspace, they are considered as coming from the same population as the initial observations. Otherwise, if they lay outside the frontier, we can confidently say that they are abnormal.
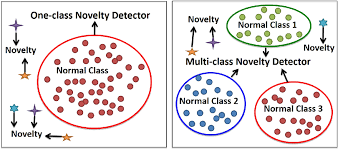
Outlier detection is also known as unsupervised anomaly detection. It is similar to novelty detection in that the goal is to separate a core of regular observations from some polluting ones, called outliers. However, in the case of outlier detection, we don’t have access to the correct-clean distribution representing the population of regular observations.
These differences are important. When approaching a business problem related to anomaly detection, it’s essential to differentiate between the quality levels of information to tackle the problem correctly.
The most commonly used techniques
Anomaly detection works by identifying outlying data and information. To correctly classify this data, we can train a machine learning algorithm exclusively for correct data (One-class SVM). This way, any time the algorithm detects any outlying or unusual data, it is flagged as a novel instance. However, sometimes the trained algorithm looks for groupings of unusual data, known as clusters (Gaussian mixtures, K-means, DBSCAN.
If all of this seems like rocket science, that’s where we come in. At Factored, we can provide you with world-class data scientists. They can help you make sense of your data and create systems to flag any unusual activity. This will help keep your company abreast of security threats, industry trends and opportunities for innovation.
Book a meeting with Factored today so we can help you build a team of expert data scientists and engineers. We will help to keep you on top of your data.




