


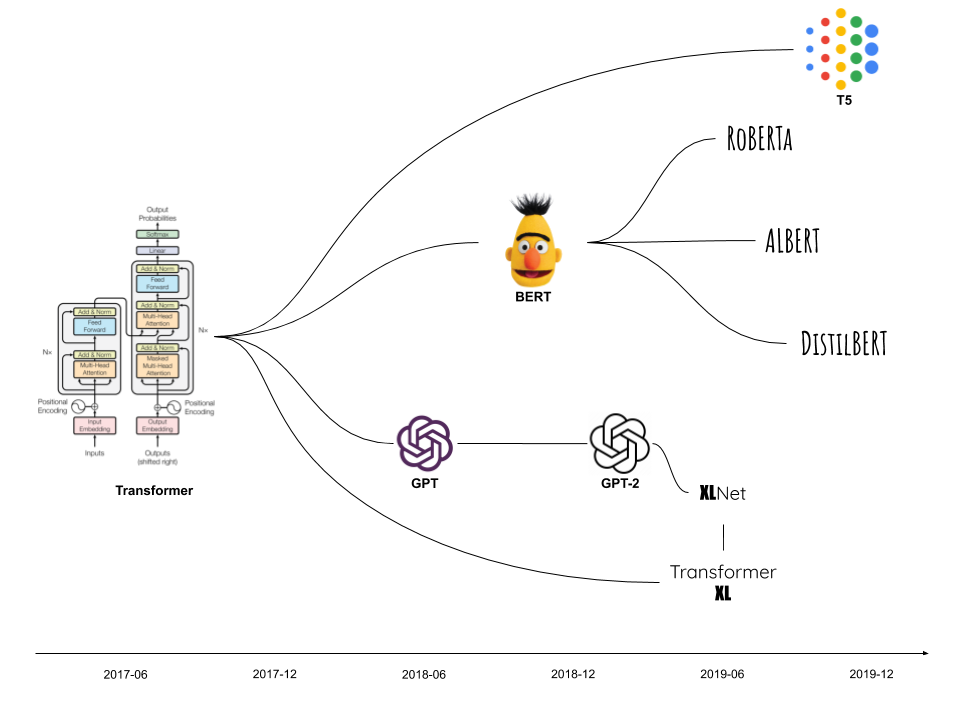
If you’re a data scientist working in the field of machine learning, you’ll no doubt be aware of all the natural language processing (NLP) BERT-like models that are taking the field by storm. With names like BERT, RoBERTa, ALBERT, DistilBERT being widely discussed, it’s important to know which is which.
If you haven’t heard of them, these are a special type of neural network used mainly in NLP, a subset of artificial intelligence that deals with text, audio and language. These models have shown remarkable success in the areas of free text, human voice audio and understanding language and have helped to improve tasks and products such as chatbots, question answering systems, speech recognition systems, summarization, sentiment analysis, topic classification, and text generation.
After reading this piece, you’ll have an intuitive understanding of both the history and evolution of these models and the circumstances under which it’s best to use each type.
Attention is all you need
Everything started in June 2017 with the iconic paper, Attention Is All You Need, by Vaswani et al, which introduced a new neural architecture called “Transformers”. This new architecture is based on the concept of attention and is composed of an encoder and a decoder. For this post, we’ll only focus on the encoder since it’s the most relevant for understanding BERT-like models.
If you’re new to the concept of Transformers, the Illustrated Transformer is a particularly useful resource to help you understand it.
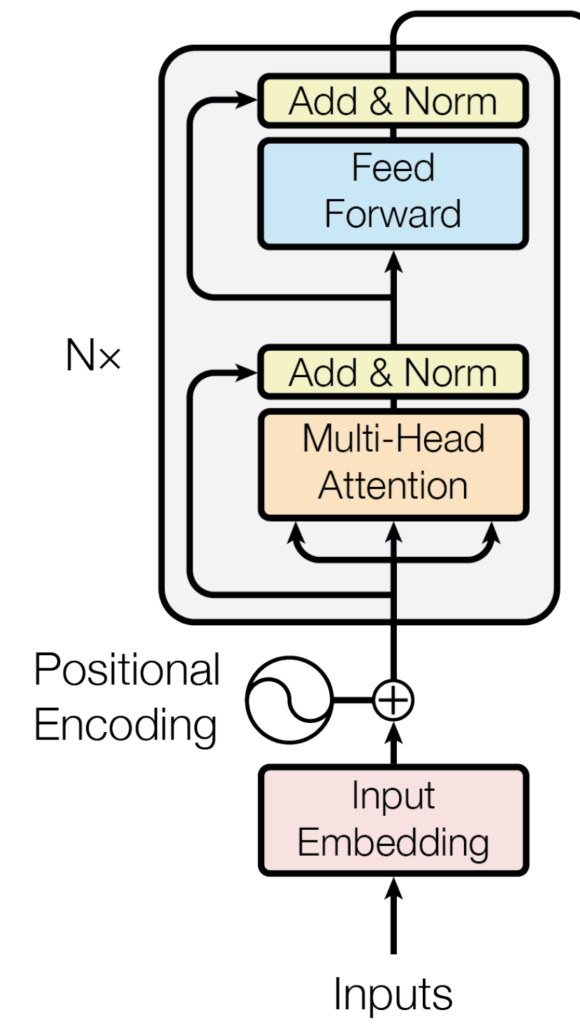
In a nutshell: the role of the Transformer is to take a sequential input and find a better representation (encoding) of the information contained in the sequence. To find this representation, it uses multi-headed self-attention and feed-forward layers.
Using BERT-like models to solve Natural Language Processing (NLP), one Transformer at a time
With an understanding of the Transformer encoder architecture, we can now go on to explore the BERT-like models. Architecture-wise, these models are essentially the same, as they all use the Transformer encoder with just a few modifications.
October 2018: BERT
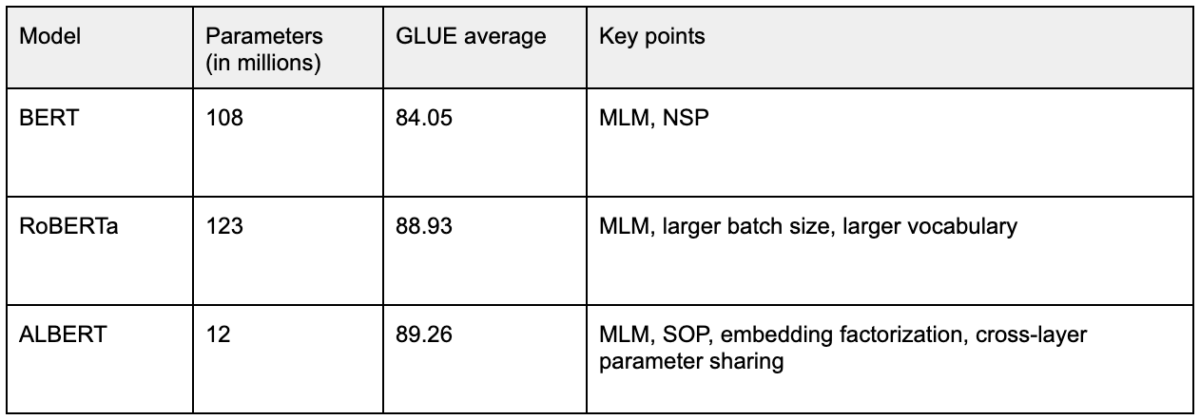
BERT was a revolution in NLP that obtained new state-of-the-art results on eleven tasks and significantly pushed the GLUE benchmark up. The GLUE benchmark is a set of tasks meant to measure natural language processing systems.
BERT models of different sizes were released: BERT-base, with a parameter count of 110 million, and BERT-large with a parameter count of 340 million.
So how does BERT work then? Pre-training doesn’t require labels, so it’s easier to get access to the required data. The pre-training consists of two tasks: masked language modeling and next sentence prediction.
The ideas are simple: Let’s pretend we’re BERT. For the masked language model task, we’ll play a fill-in-the-blank game. Ready? Let’s go:
“Is _______ learning going to solve natural _______ processing and allow communication between _______ and machines?”
Which words do you think go in the blanks?
We would, ideally, like the model to guess the words “deep”, “language” and “humans”. And through this task, BERT obtains good language representations.
The second task is the next sentence prediction, and it is about checking whether a pair of sentences are absolute nonsense or not. For example:
Sentence 1: “When I was younger I went on a trip through Europe.”
Sentence 2: “but tacos taste better.”
Is Sentence 2 related to Sentence 1?
Answer: Absolutely not. Good, this should help BERT understand relationships between sentences, and hopefully obtain better language representations. Or at least it should in theory…
July 2019: RoBERTa
RoBERTa started questioning many of BERT’s design choices and managed to beat BERT in all of the tasks set out in the GLUE benchmark.
Is the “Sentence 2” prediction sentence in the above BERT example really necessary? It turns out it isn’t, and it can even be helpful to remove it.
Would a larger batch size improve the results? Well, yes. RoBERTa increased batch size from 256 to 2048. You’re probably scoffing at me now thinking something along the lines of “I definitely can’t train that on my GPU – I don’t have those machines with 64GB of GPU memory.” Turns out the authors used gradient accumulation, which allowed them to train using large batch sizes even with low memory resources. This technique can easily be integrated with deep learning frameworks such as Keras, as seen in this post.
Also, what if we were to use a larger range of vocabulary? Turns out this also helped, as RoBERTa increased the vocabulary range from 30k to 50k. This implies that the parameter count of RoBERTa is higher than that of the BERT models, at 123 million parameters for RoBERTa base and 354 million parameters for RoBERTa large.
Is it efficient to have so many parameters? This was the question that led to the birth of a new member of the BERT family…
September 2019: ALBERT
ALBERT: is a lite BERT. The idea behind ALBERT is to make BERT more parameter-efficient, achieving the same (or better) results with fewer parameters. For parameter reduction, ALBERT implements two techniques:
- Factorized embedding parameterization: Instead of having a large embedding matrix, we break it down into two smaller matrices.
- Cross-layer parameter sharing: Models like BERT and RoBERTa have multiple Transformer layers, and each of those layers have their own, independent parameters. ALBERT takes a different approach: let’s re-use the same parameters through the layers. This drastically reduces the parameters, making ALBERT a much more practical model for NLP tasks. This idea makes sense since it has been found that there was some redundancy in operations performed in different layers, particularly for attention parameters. For example, not all attention heads are used and in some layers just one head is enough.
These two techniques facilitate a significant reduction in parameter count and training time compared to their BERT counterparts. ALBERT large (18 million parameters) obtains similar results to BERT base (108 million parameters). ALBERT xlarge (60 million parameters) obtains similar results to BERT large (334 million parameters).
Finally, ALBERT keeps the masked language modelling task, but replaces BERT’s next sentence prediction with a sentence order prediction task, which aims to learn coherence. The idea is to determine which sentence comes first. Let’s try it out:
Sentence 1: “For example, ALBERT-large has about 18x fewer parameters compared to BERT-large, 18M versus 334M”
Sentence 2: “An ALBERT-xlarge configuration with H = 2048 has only 60M parameters and an ALBERT-xxlarge configuration with H = 4096 has 233M parameters.”
Which one comes first?
Hopefully you noticed that this task is harder than next sentence prediction, and should force the model to learn better representations.
Before moving on, let’s recap the key points of each of the models seen:
There are many more Transformer-based models out there, each of them with their own advantages and challenges. I encourage you to check them out and analyze them in the same way that we’ve done in this post.
Which model should you start with? In my experience, ALBERT is a safe starting point – the reduced parameters make it easier to train than the other models and often achieves promising results. From there I would scale up if needed, exploring different models according to results found in error analysis.
What’s next? Evolving the Transformer
Have you noticed something? All of these models use the same basic component: the Transformer, and only focus on changing the training details. What if we changed the Transformer?
The Evolved Transformer uses Neural Architecture Search (NAS) to find a new Transformer architecture, and the following is the encoder block that it came up with to compare the original Transformer encoder block:
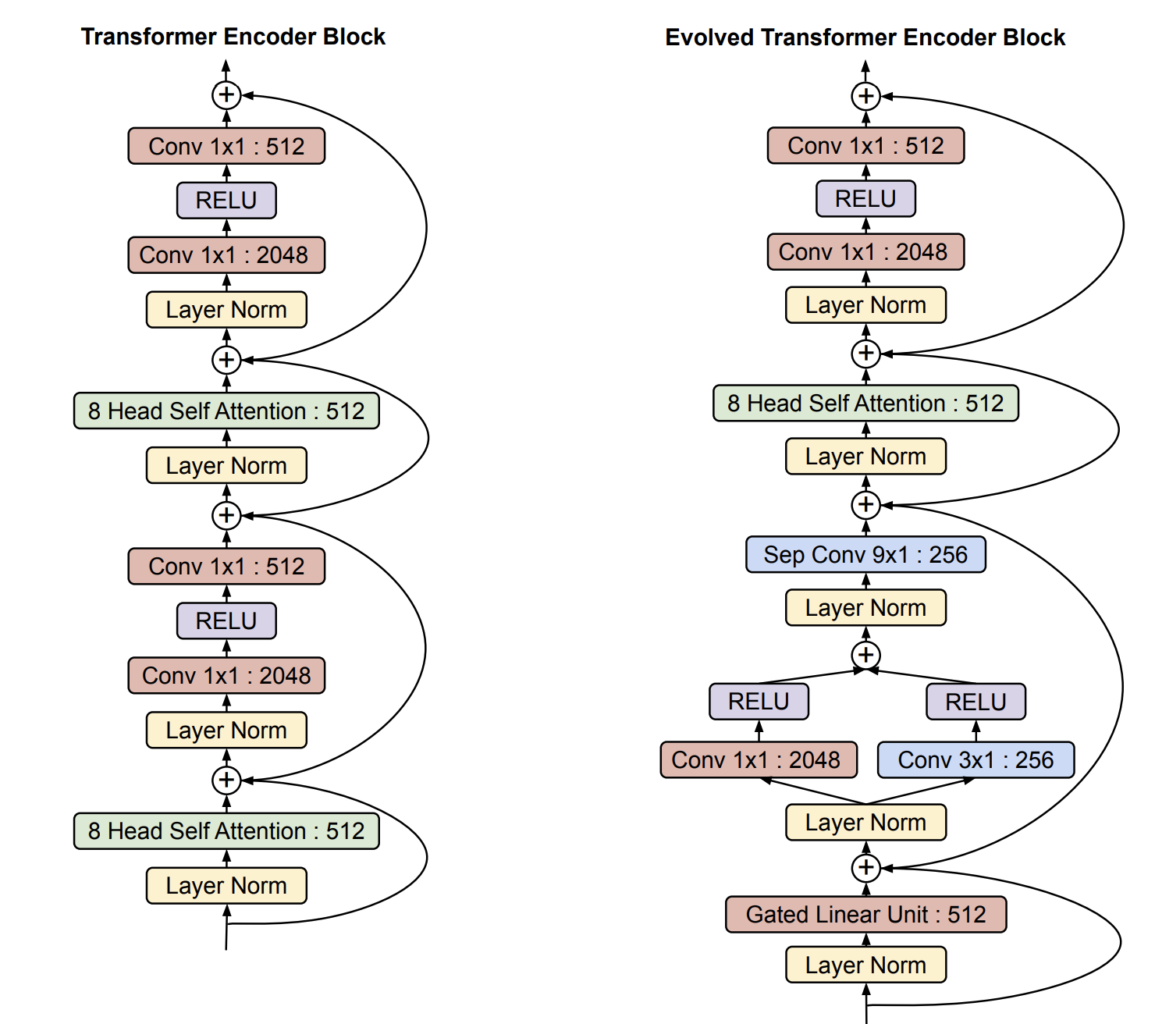
This diagram might look a bit different to the one we saw earlier, but it’s exactly the same – the 1×1 convolutional layers are equivalent to the dense layers in the previous diagram. Let’s analyze the differences between the original and the Evolved Transformers.
The Evolved Transformer keeps the multi-headed attention mechanisms and the final feed-forward layers, but notice that it uses a different mechanism before the multi-headed attention, where it splits paths and applies convolutions of different filter sizes.
As shown below, the Evolved Transformer obtains better results with fewer parameters than the traditional Transformers, making it an interesting choice to try BERT-like, Evolved Transformer-based models for NLP.
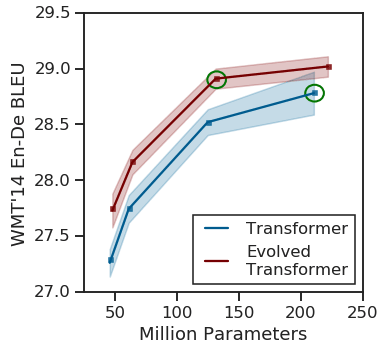
This approach to finding an alternative Transformer focused on improving performance. The Reformer, on the other hand, focused on improving memory-efficiency and long-sequence usability without sacrificing performance, allowing it to fit large models in memory.
Conclusions
The landscape of NLP is still evolving. Transformer-based models and self-supervised learning mechanisms have shown promising results and new ideas are constantly being developed. Hopefully this post has helped to clarify the current state and future direction of Transformer-based models in NLP.
I encourage you to think about the flaws of current models and training strategies—what do you think a new architecture or training mechanism should look like? Perhaps you’ll go on to create the next member of the BERT family!




